PØDA: Prompt-driven Zero-shot Domain Adaptation
ICCV 2023

TL;DR : We propose Prompt-driven Instance Normalization (PIN), an extremely simple style augmentation/mining method guided by a single text description. PIN is plug-and-play, and the resulting styles can be used to boost semantic segmentation, object detection, and image classification on unseen domains described by a single prompt.
Abstract
Domain adaptation has been vastly investigated in computer vision but still requires access to target images at train time, which might be intractable in some uncommon conditions. In this paper, we propose the task of ‘Prompt-driven Zero-shot Domain Adaptation’, where we adapt a model trained on a source domain using only a general description in natural language of the target domain, i.e., a prompt. First, we leverage a pretrained contrastive vision-language model (CLIP) to optimize affine transformations of source features, steering them towards the target text embedding while preserving their content and semantics. To achieve this, we propose Prompt-driven Instance Normalization (PIN). Second, we show that these prompt-driven augmentations can be used to perform zero-shot domain adaptation for semantic segmentation. Experiments demonstrate that our method significantly outperforms CLIP-based style transfer baselines on several datasets for the downstream task at hand, even surpassing one-shot unsupervised domain adaptation. A similar boost is observed on object detection and image classification
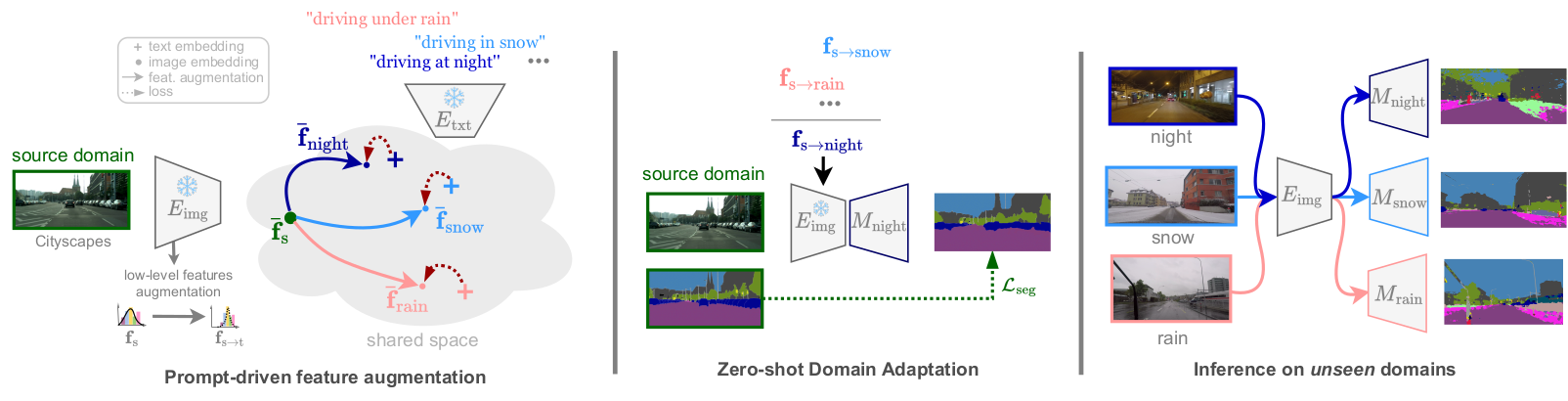
Overview of PØDA
(Left) PØDA leverages frozen CLIP image encoder and a single textual prompt of an unseen target domain to optimize affine transformations of low-level features. (Middle) Zero-shot domain adaptation is achieved by finetuning a segmenter model (M) on the feature-augmented source domain with our optimized transformations. (Right) This enables inference on unseen domains.
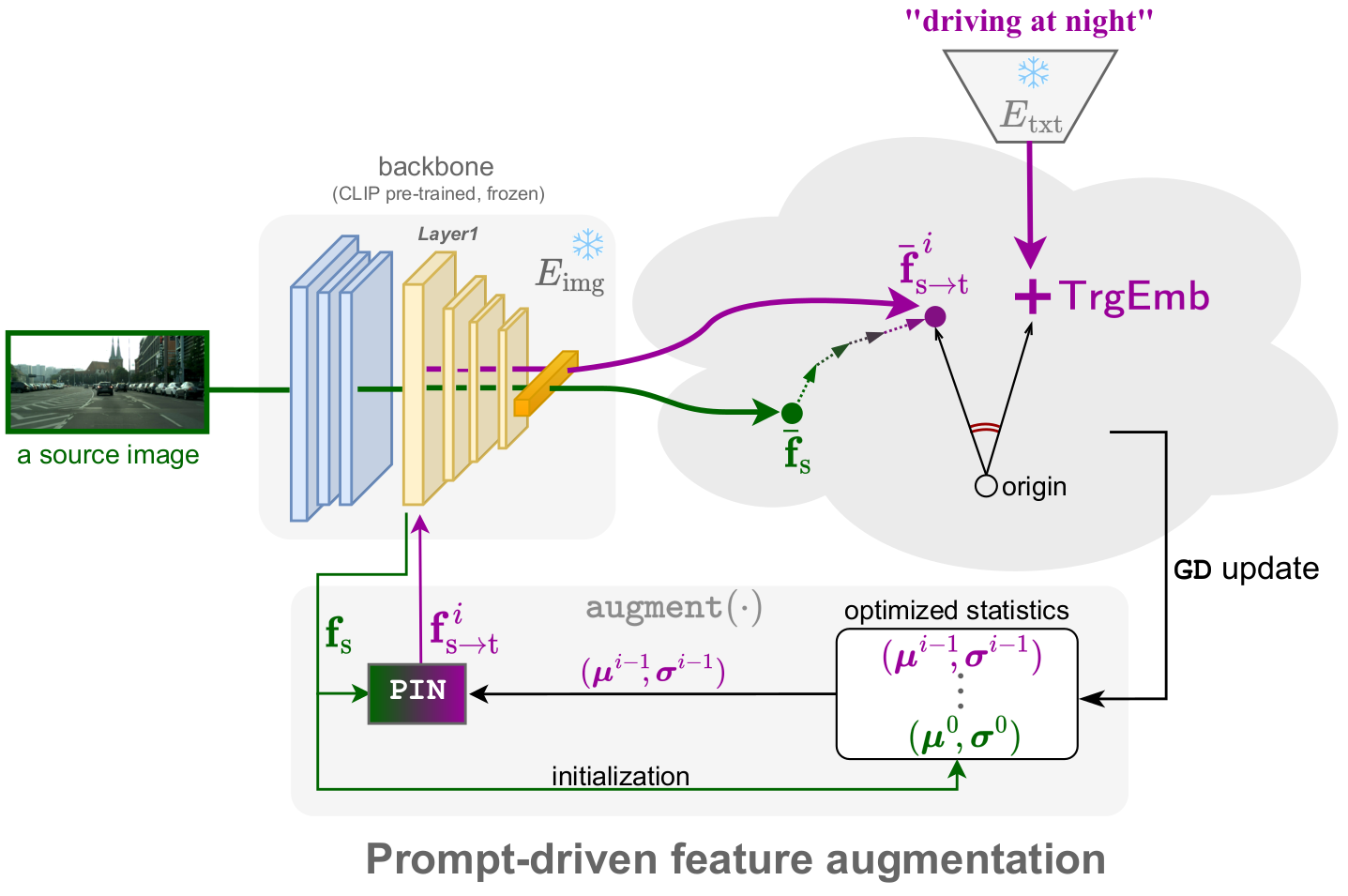
Method
PØDA optimizes low-level feature channel's statistics using a novel Prompt-driven Instance Normalization (PIN), such that the cosine similarity between the targeted representation matches the representation of the prompt describing the target domain. These optimized statistics are then applied to stylize the features, and the network is subsequently fine-tuned on them.
PØDA's qualitative results on unseen youtube videos
PØDA's qualitative results on some uncommon conditions

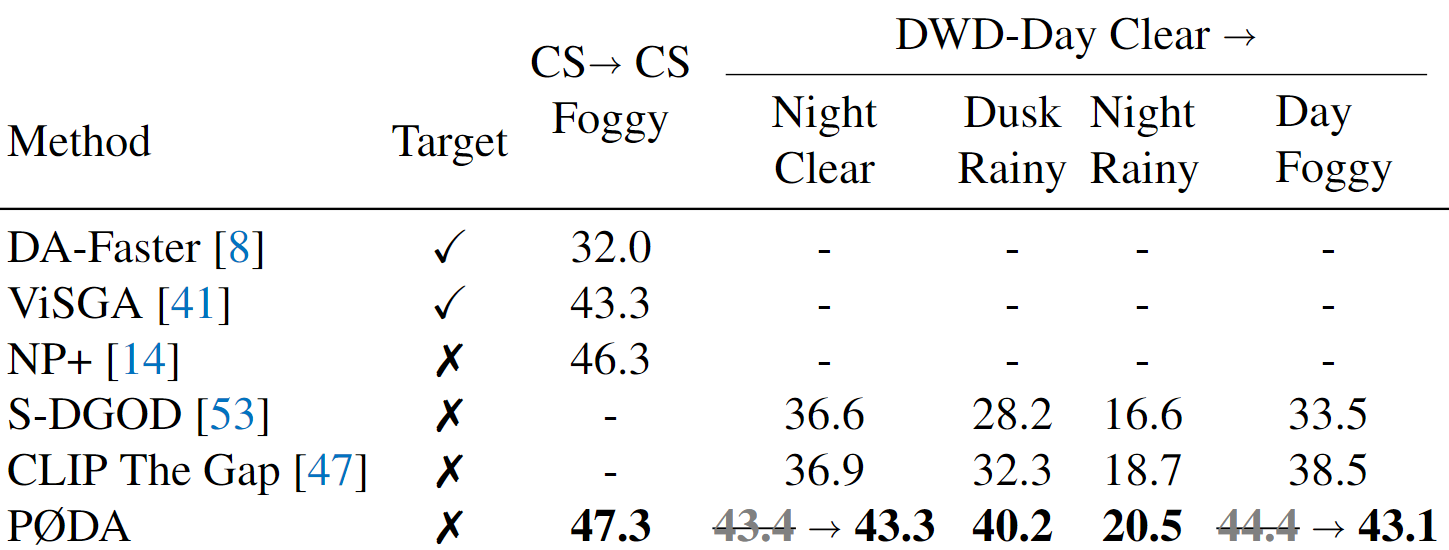
PØDA on Single-Domain Generalized Object Detection (Single-DGOD)
Citation
@InProceedings{fahes2023poda,
title={P{\O}DA: Prompt-driven Zero-shot Domain Adaptation},
author={Fahes, Mohammad and Vu, Tuan-Hung and Bursuc, Andrei and P{\'e}rez, Patrick and de Charette, Raoul},
booktitle={ICCV},
year={2023}}