PaSCo
Urban 3D Panoptic Scene Completion with
Uncertainty Awareness
CVPR 2024 Oral, Best Paper Award Candidate
Click and drag to interact
Abstract
We propose the task of Panoptic Scene Completion (PSC) which extends the recently popular Semantic Scene Completion (SSC) task with instance-level information to produce a richer understanding of the 3D scene. Our PSC proposal utilizes a hybrid mask-based technique on the non-empty voxels from sparse multi-scale completions. Whereas the SSC literature overlooks uncertainty which is critical for robotics applications, we instead propose an efficient ensembling to estimate both voxel-wise and instance-wise uncertainties along PSC. This is achieved by building on a multi-input multi-output (MIMO) strategy, while improving performance and yielding better uncertainty for little additional compute. Additionally, we introduce a technique to aggregate permutation-invariant mask predictions. Our experiments demonstrate that our method surpasses all baselines in both Panoptic Scene Completion and uncertainty estimation on three large-scale autonomous driving datasets.
Demo
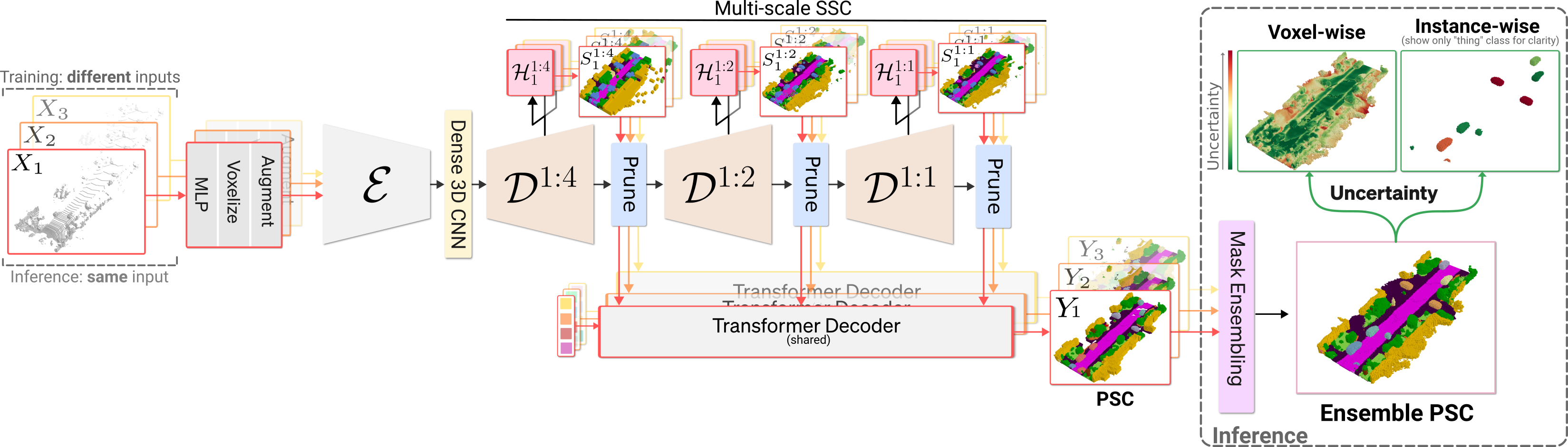
Overview of our method
Panoptic Scene Completion Comparison
Uncertainty Estimation Comparison
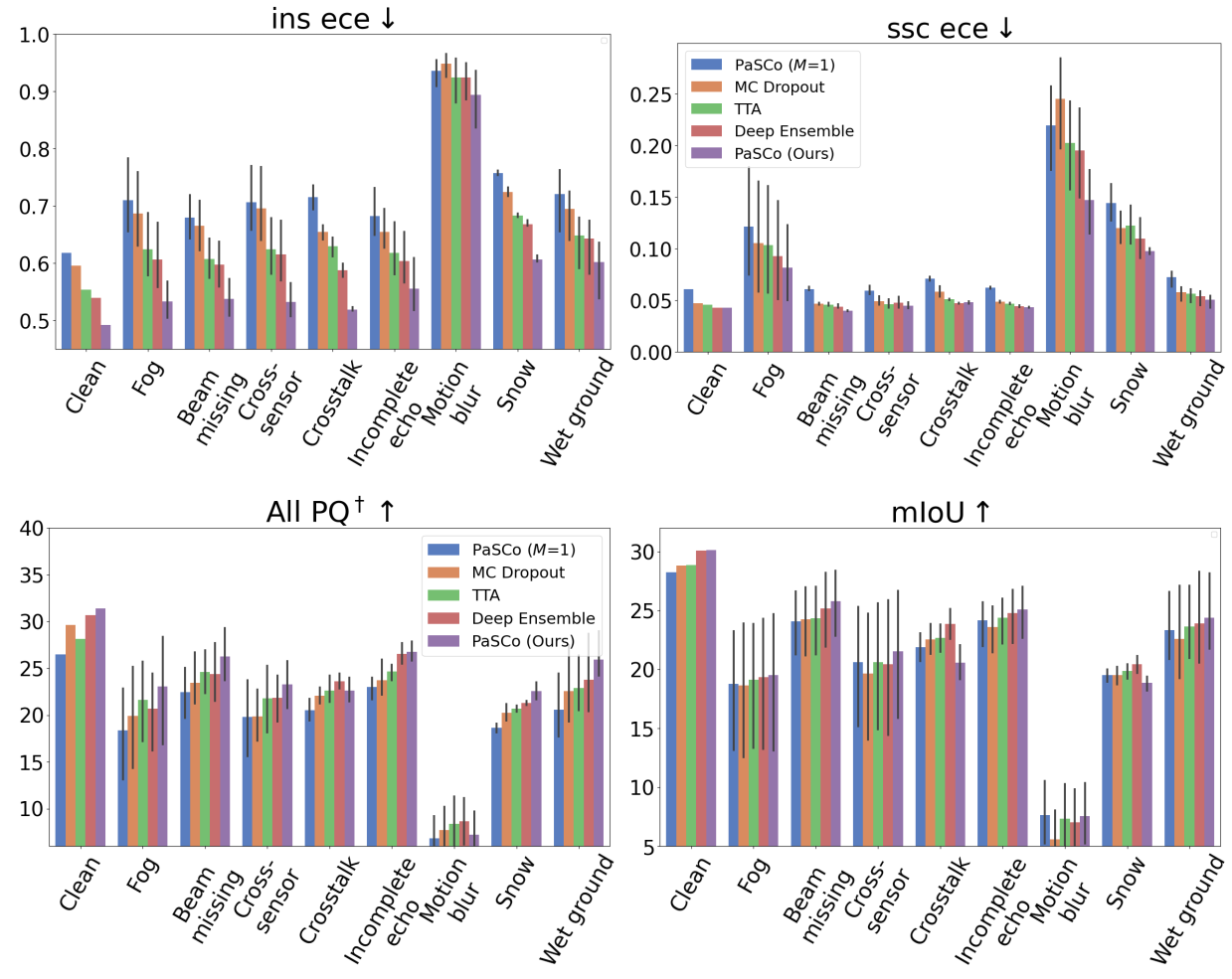
Robusness Evaluation on Robo3D
Citation
@InProceedings{cao2024pasco,
title={PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness},
author={Anh-Quan Cao and Angela Dai and Raoul de Charette},
year={2024},
booktitle = {CVPR},
}