SceneRF
Self-Supervised Monocular 3D Scene Reconstruction
with Radiance Fields
ICCV 2023

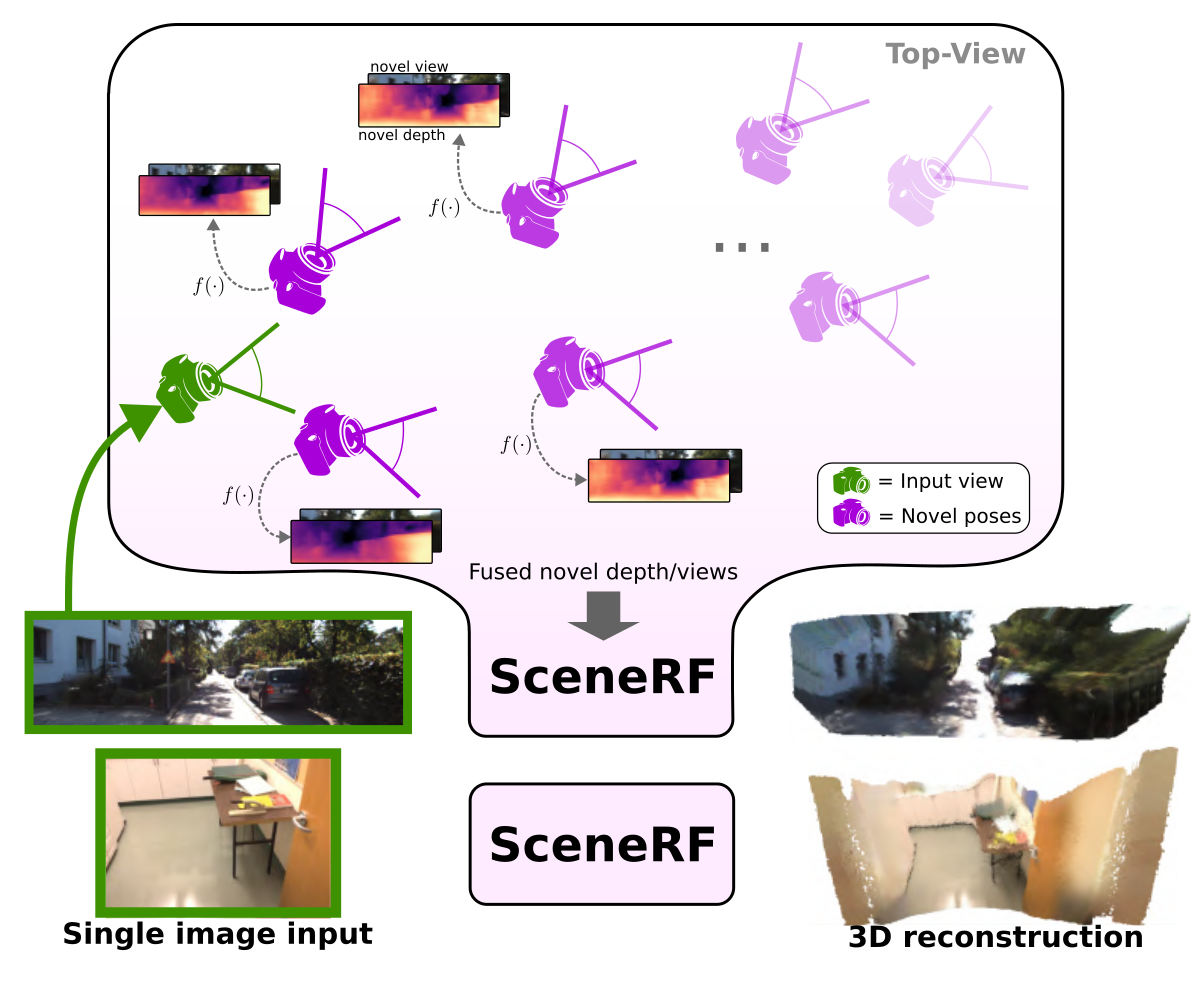
Abstract
3D reconstruction from 2D image was extensively studied, training with depth supervision. To relax the dependence to costly-acquired datasets we propose SceneRF, a self-supervised monocular scene reconstruction method using only posed image sequences for training. Fueled by the recent progress in neural radiance fields (NeRF) we optimize a radiance field though with explicit depth optimization and a novel probabilistic sampling strategy to effi- ciently handle large scenes. At inference, a single input image suffices to hallucinate novel depth views which are fused together to obtain 3D scene reconstruction. Thorough experiments demonstrate that we outperform all recent baselines for novel depth views synthesis and scene reconstruction, on indoor BundleFusion and outdoor SemanticKITTI.
Semantic KITTI (val. set)
A single image input
Novel depths/views synthesis
3D reconstruction (Mesh)












BundleFusion (val. set)
A single image input
Novel depths/views synthesis
3D reconstruction (Mesh)








Overview of our method
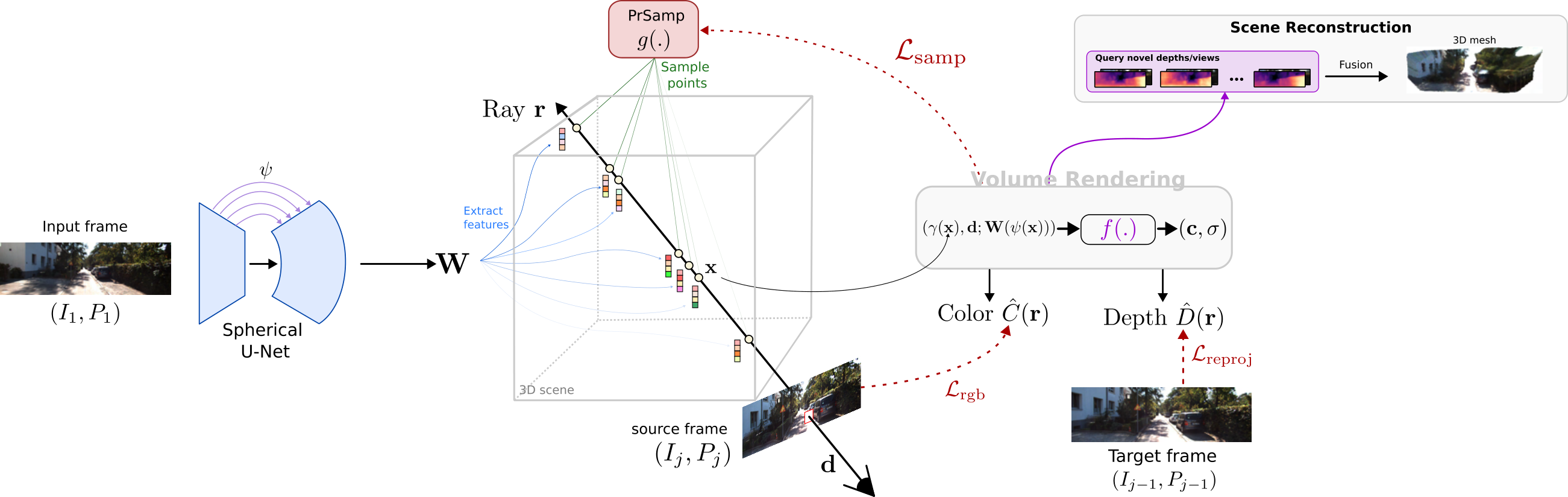 Our method leverages generalizable neural radiance field (NeRF) to generate novel depth views,
conditioned on a single input frame. During training for each ray in addition to color,
we explicitly optimize depth with a reprojection loss (Sec. 3.1), introduce a Probabilistic Ray Sampling strategy (PrSamp, Sec. 3.2)
to sample points more efficiently. To hallucinate features outside the input FOV, we propose a spherical U-Net (Sec. 3.3).
Finally, the synthesized depths are used for scene reconstruction (Sec. 3.4).
Our method leverages generalizable neural radiance field (NeRF) to generate novel depth views,
conditioned on a single input frame. During training for each ray in addition to color,
we explicitly optimize depth with a reprojection loss (Sec. 3.1), introduce a Probabilistic Ray Sampling strategy (PrSamp, Sec. 3.2)
to sample points more efficiently. To hallucinate features outside the input FOV, we propose a spherical U-Net (Sec. 3.3).
Finally, the synthesized depths are used for scene reconstruction (Sec. 3.4).
Qualitative results
Input




Trajectory
Novel depths (and views)


















3D Reconstruction (Mesh)




Citation
If you find this project useful for your research, please cite
@InProceedings{cao2023scenerf,
author = {Cao, Anh-Quan and de Charette, Raoul},
title = {SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields},
booktitle={ICCV},
year={2023},
}
Acknowledgements
The work was partly funded by the French project SIGHT (ANR-20-CE23-0016) and conducted in the SAMBA collaborative
project, co-funded by BpiFrance in the Investissement d’Avenir Program. It was performed using HPC resources from GENCI–IDRIS (Grant 2021-AD011012808, 2022-AD011012808R1, and 2023-AD011014102). We thank Fabio Pizzati and Ivan Lopes for their kind proofreading.
Overview of our method
Qualitative results
| Input | ||||
|
|
|
|
|
| Trajectory | Novel depths (and views) | |||
|
|
|
|
|
|
|
|
|
|
| 3D Reconstruction (Mesh) | ||||
|
|
|
|
|
Citation
@InProceedings{cao2023scenerf,
author = {Cao, Anh-Quan and de Charette, Raoul},
title = {SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields},
booktitle={ICCV},
year={2023},
}